What is Natural Language
Processing?
How computers learned to read, listen, understand, and speak back — a deep, friendly, and comprehensive guide to NLP, the technology powering chatbots, translators, voice assistants, and modern AI.
What Is Natural Language Processing?
Imagine if your phone could not only hear you talking but truly understand what you meant — even when you mumble, use slang, or make a joke. That is exactly what Natural Language Processing makes possible. It is the technology that lets computers read, listen, and make sense of the way humans actually communicate.
Natural Language Processing — usually shortened to NLP — is a branch of artificial intelligence (AI) where computers are taught to work with human language. This includes text you type, speech you say aloud, and even handwritten notes. The goal is to make computers understand language the same way a person would — grasping not just the individual words but the full meaning, emotion, context, and intent behind them.
Human language is wonderfully complex. The same sentence can mean completely different things depending on who says it, how they say it, and what happened just before. The word “sick” can mean someone is ill — or that something is amazingly cool. The phrase “I can’t recommend this restaurant enough” could mean you absolutely love it, or that you hate it so much you refuse to recommend it. Humans navigate these subtleties effortlessly; teaching computers to do the same has been one of the greatest challenges — and triumphs — of modern computer science.
Natural Language Processing is the engineering discipline of building machines that can understand, interpret, and generate human language — turning the messy, ambiguous, and beautiful complexity of words into something computers can act on.— Synthesised definition, 2026
You know how you can talk to Siri or Google and it understands what you want? Or how your phone autocorrects your messages? Or how Google Translate turns your English into Hindi? All of that is NLP at work. It is the part of AI that handles words and language — reading them, understanding them, and writing them back.
Why Does NLP Matter?
We are living through an explosion of language data. Every second, millions of emails, tweets, reviews, medical notes, legal documents, and customer service chats are created. Without NLP, all of that text is just noise. With NLP, it becomes a goldmine of insight, action, and connection.
Think about just one corner of the internet — customer reviews. A large retailer might receive half a million product reviews every month. No team of human readers could process that volume. But an NLP system can scan every single review in minutes, categorise the feedback, identify which products are loved and which are problematic, and flag emerging safety concerns — all without a human reading a single line.
Now scale that thinking to hospitals analysing patient records, banks monitoring fraud in millions of transactions, governments scanning legislation for contradictions, and social platforms filtering hate speech in real time. NLP is the quiet engine running behind all of it.
Breaking Language Barriers
NLP-powered translation tools allow people who speak different languages to communicate freely, access information, and participate in the global economy without needing to learn another tongue.
Processing at Scale
Humans can read roughly 200 words per minute. An NLP system processes millions of documents per second — making it possible to extract insights from datasets that would take a human lifetime to read.
Accessibility
Voice-based interfaces powered by NLP let people with visual impairments, mobility limitations, or dyslexia interact with technology as naturally as everyone else — through speech and sound.
Traditional computer systems only work with structured data — neatly organised rows and columns of numbers. Nearly 80% of all real-world business data is unstructured: emails, contracts, doctor’s notes, and social media posts. NLP is the technology that transforms this unstructured human language into structured information that computers can reason about, search through, and act on.
NLP vs NLU vs NLG — The Language AI Family
NLP is the umbrella term, but underneath it live two closely related cousins: NLU (Natural Language Understanding) and NLG (Natural Language Generation). Together, they cover the full loop of computer-language interaction — listening and reading in, thinking it through, then speaking or writing back out.
Natural Language Processing. The broad field covering all techniques for working with human language — including both understanding it and generating it. NLP encompasses NLU and NLG.
Natural Language Understanding. The sub-field focused on comprehension — figuring out the intended meaning, sentiment, and context behind words. When Siri understands your question, that is NLU.
Natural Language Generation. The sub-field focused on producing coherent, meaningful text or speech from data or intent. When ChatGPT writes a paragraph, that is NLG in action.
A Brief History of NLP — From Punch Cards to ChatGPT
NLP is not a new idea. Researchers have been trying to get computers to understand language for over seventy years — a journey full of breakthroughs, frustrations, dead ends, and world-changing discoveries.
Alan Turing Proposes the Imitation Game
British mathematician Alan Turing published “Computing Machinery and Intelligence,” proposing a test where a machine would be considered intelligent if a human could not distinguish its text responses from those of another human. This planted the first seed of conversational AI.
Georgetown-IBM Experiment
Researchers at Georgetown University and IBM demonstrated the first machine translation system, automatically converting 60 Russian sentences into English. They boldly predicted that machine translation would be fully solved within three to five years — a forecast that turned out to be wildly optimistic.
ELIZA — The First Chatbot
MIT’s Joseph Weizenbaum created ELIZA, a program that simulated a psychotherapist by reflecting users’ statements back as questions. ELIZA worked purely on pattern matching, with no real understanding — yet many users found it convincingly human-like. It was both impressive and a warning about the gap between appearance and genuine comprehension.
Rule-Based Systems & Statistical Methods Emerge
NLP researchers built elaborate hand-crafted rule systems — dictionaries of grammatical rules that computers followed mechanically. By the late 1980s, statistical approaches (using probability and data patterns) began to overtake rule-based systems, proving more flexible and robust.
Spam Filters, Search Engines & Early Chatbots
Statistical NLP made practical products possible for the first time. Email spam filters could distinguish junk from legitimate messages. Early search engines learned to match queries to relevant documents. Companies began investing in NLP as a real commercial technology.
Deep Learning Transforms NLP
Word embeddings (representations that capture meaning), recurrent neural networks, and long short-term memory networks gave NLP its biggest capability jump yet. Systems could now understand context across entire sentences and paragraphs, not just individual words.
“Attention Is All You Need” — The Transformer Revolution
Google researchers published a paper introducing the Transformer architecture — a new way of processing language that could consider all words in a sentence simultaneously rather than one at a time. This single paper triggered the modern NLP era and led directly to BERT, GPT, and all the major AI assistants of today.
The Age of Large Language Models
ChatGPT, Google Gemini, Meta LLaMA, and other large language models demonstrated that NLP had crossed a threshold — machines could now hold extended conversations, write essays, debug code, translate languages, and summarise books at near-human quality. NLP moved from a specialist tool to a mass-market technology used by hundreds of millions of people daily.
How Computers Read Language — The Core Problem
Computers are fundamentally very clever calculators. They work with numbers — not words, sentences, or feelings. The deepest challenge of NLP is finding ways to translate the incredible richness of human language into mathematical structures a computer can reason about.
When you read the word “dog,” your brain instantly lights up with associations — fur, barking, loyalty, your neighbour’s annoying terrier. A computer sees only a sequence of characters: d-o-g. Getting the computer to understand that “dog” and “puppy” are related, that “dog” and “cat” are both pets, and that “dog” in a legal document might mean something entirely different — this is the core problem NLP spends its energy solving.
Human language is ambiguous (the same words mean different things), contextual (meaning changes with surrounding words), figurative (idioms like “kick the bucket” mean something completely different from their literal reading), evolving (new words and meanings appear constantly), and noisy (full of typos, slang, and grammatical mistakes). Each of these dimensions represents a major engineering challenge that NLP must overcome.
The Language Ambiguity Problem
The Core NLP Pipeline — Step by Step
When an NLP system processes a sentence, it does not work in one single step. Instead, it runs the text through a series of stages — like an assembly line — each one peeling away another layer of meaning until the computer finally understands what the human was trying to say.
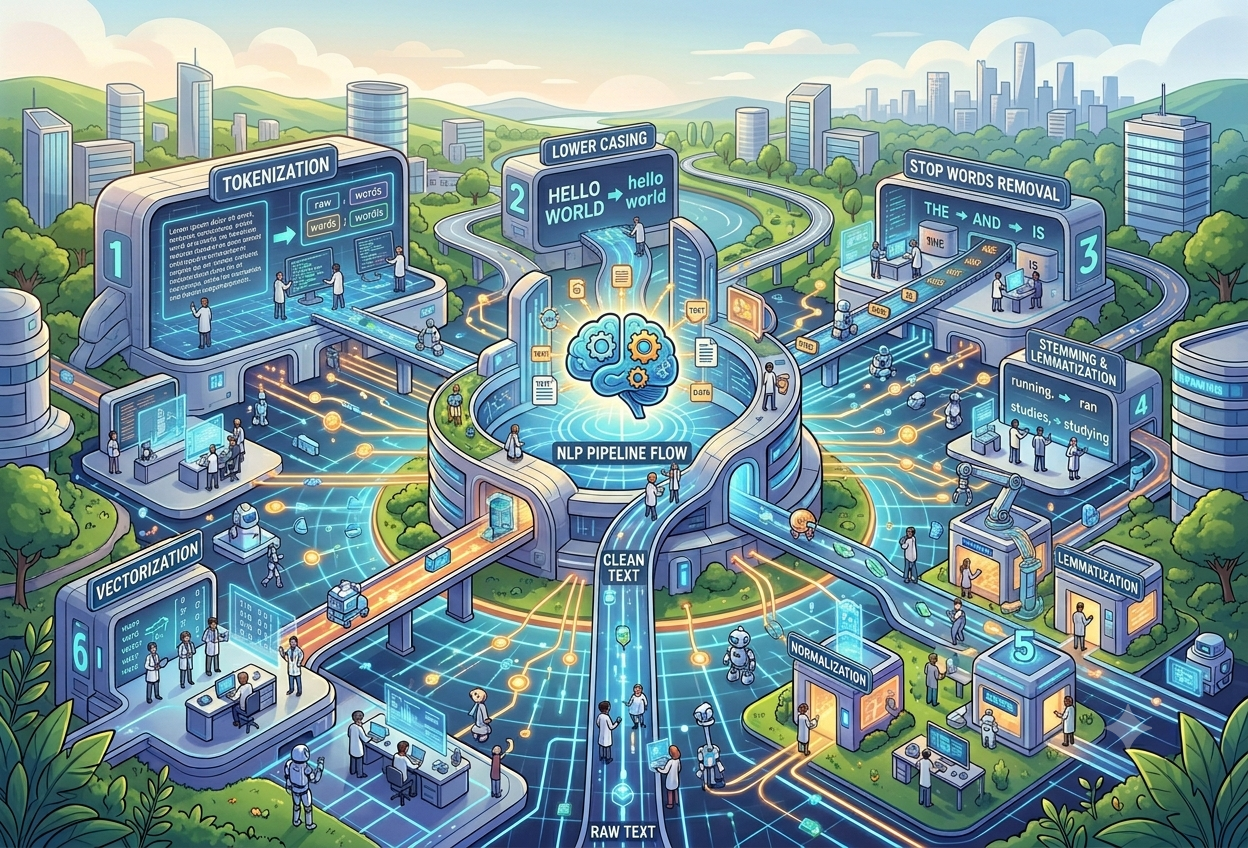
Tokenisation — Splitting into Pieces
The very first step is breaking a continuous stream of text into individual units called tokens. Usually these are words, but they can also be sub-words (useful for handling new or rare words) or even individual characters. “The dog barked loudly” becomes four tokens: “The”, “dog”, “barked”, “loudly”. This creates the building blocks every later step works with.
Part-of-Speech Tagging — What Is Each Word Doing?
After tokenisation, each word is labelled with its grammatical role: noun, verb, adjective, adverb, pronoun, preposition, and so on. “She runs fast” — “runs” is a verb. “She has two runs in the 100m” — “runs” is a noun. POS tagging helps the system understand how each word functions in its particular sentence.
Named Entity Recognition (NER) — Spotting Important Names
NER identifies and categorises special names in text — people (Elon Musk), organisations (Google), locations (Mumbai), dates (14th March), currencies (₹500), and more. This is essential for tasks like summarising news articles, extracting information from contracts, or identifying patients’ names in medical records.
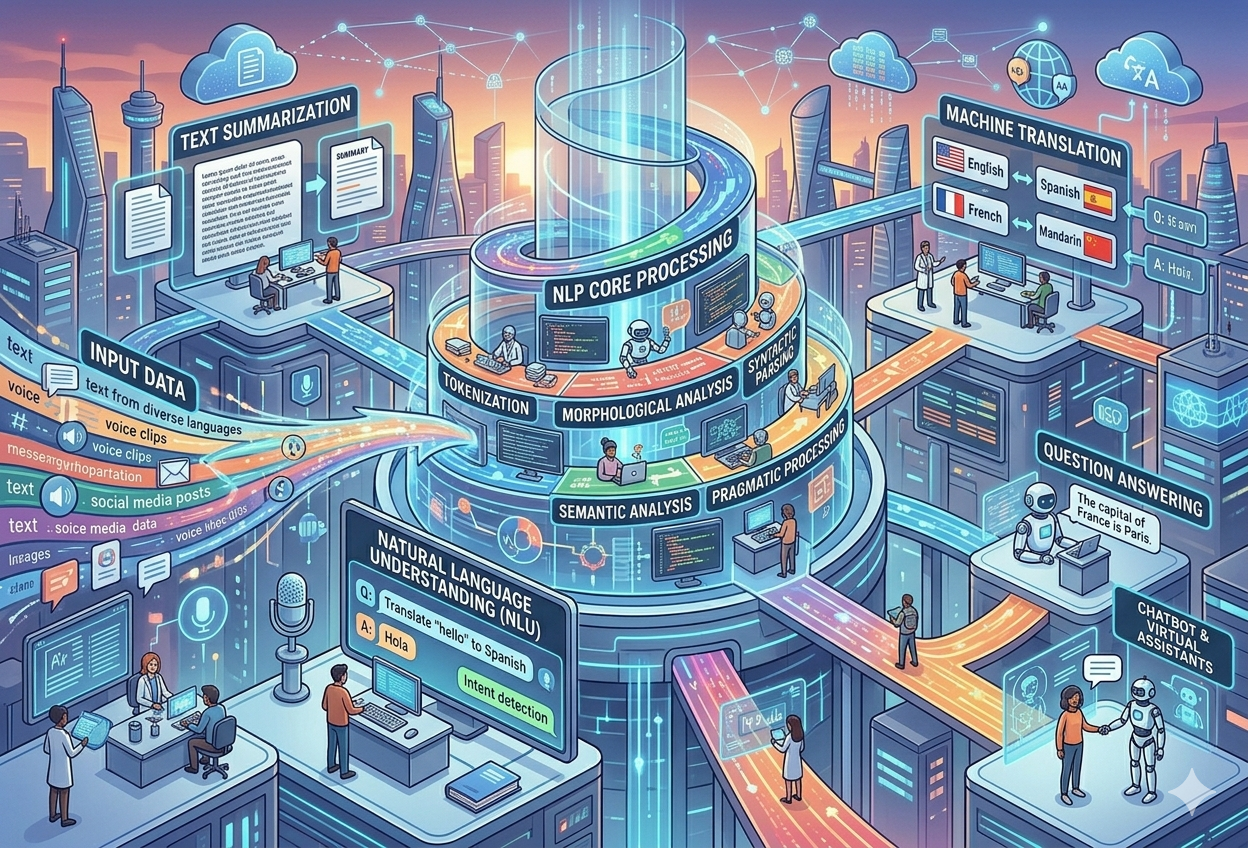
Parsing — Understanding Sentence Structure
Parsing analyses how words relate to each other grammatically. It builds a tree structure showing which words modify which. Understanding that “the tall man who wore the red hat” is the subject of the sentence, not a separate clause, requires parsing. Without it, a system cannot reliably understand who did what to whom.
Semantic Analysis — What Does It Actually Mean?
This is where NLP goes from grammar to genuine meaning — understanding intent, resolving ambiguous words using context, handling figurative language, and building a coherent representation of what the sentence is communicating. This is the hardest step and where most of the sophisticated machine learning is applied.
Key NLP Techniques — The Toolkit
Over seventy years of research has produced a rich toolkit of NLP techniques. Each one is a specialised instrument for a different aspect of the language problem — like the different tools in a surgeon’s kit, each designed for a specific job.
Determines whether text expresses a positive, negative, or neutral emotion. Businesses use this to scan thousands of customer reviews and social media posts to understand how people feel about their products.
Most UsedAutomatically converts text or speech from one language to another while preserving the original meaning and context. Google Translate processes over 100 billion words per day using NLP.
Identifies and classifies real-world entities — people, places, organisations, dates, currencies — within text. Vital for document intelligence, news summarisation, and medical record analysis.
Condenses long documents into short, informative summaries. Two approaches exist: extractive (picking the most important existing sentences) and abstractive (rewriting the content in fewer words).
Discovers the hidden themes within a large collection of documents without being told what to look for. Useful for analysing thousands of customer complaints to identify the most common issues.
Automatically identifies the most important words and phrases in a piece of text. Powers search engine optimisation, content tagging, and business intelligence dashboards.
Takes a natural-language question and finds (or generates) the correct answer from a knowledge base or a given document. This powers FAQ bots and voice assistants like Alexa and Siri.
A specialised form of sentiment analysis that detects hostile content including threats, hate speech, harassment, and defamatory language — essential for content moderation on social platforms.
Detects and corrects grammatical errors in written text. Tools like Grammarly and the grammar checker in Microsoft Word use NLP models trained on millions of correct and incorrect sentence pairs.
Three Approaches to Building NLP Systems
Not all NLP systems are built the same way. Over the decades, researchers have developed three broad approaches — each with its own philosophy, strengths, and ideal use cases.
Rule-Based NLP
The original approach. Human linguists write explicit grammatical rules that the computer follows. “If a sentence contains the word ‘not’ before a positive word, classify it as negative.” These systems are highly predictable and explainable but require enormous human effort to build and maintain, and they break down quickly when encountering language they were not designed for.
Statistical NLP
Rather than writing rules by hand, statistical systems learn patterns from large datasets of text. They calculate the probability that a sequence of words carries a certain meaning. This approach was dominant from the 1990s through the early 2010s and produced the first practical spam filters, search engines, and translation systems.
Neural / Deep Learning NLP
Modern NLP uses artificial neural networks — mathematical structures loosely inspired by the brain — to learn language patterns at a scale and depth that statistical methods could never reach. These systems consume billions of words during training and develop rich internal representations of meaning. All the state-of-the-art AI assistants today use this approach.
Hybrid Approaches
In practice, most production NLP systems combine approaches. A deep learning model might handle the understanding, while a rule-based system handles specific required output formats. A statistical component might filter candidates before the neural model makes the final decision. Real-world NLP is more pragmatic than theoretical.
| Approach | Learns From | Best For | Major Weakness |
|---|---|---|---|
| Rule-Based | Explicit human-written rules | Structured, predictable text (legal, medical forms) | Cannot handle language outside the rules |
| Statistical | Large text corpora + probability | Spam detection, basic classification | Requires feature engineering; misses deep meaning |
| Neural (Deep Learning) | Billions of words end-to-end | Translation, conversation, generation | Needs massive data and compute; “black box” |
Core Technologies Inside Modern NLP
Under the hood of every NLP system are layers of interconnected technologies — mathematical tools and algorithmic structures that together give the system its ability to process language. Here are the most important ones.
Word Embeddings — Turning Words into Numbers
For a computer to work with words, those words need to become numbers. Word embeddings are mathematical representations that place words in a multi-dimensional space where similar words are positioned close together. In this space, “king” minus “man” plus “woman” actually equals something very close to “queen” — the model has somehow captured gender and royalty as measurable dimensions.
Recurrent Neural Networks (RNNs) & LSTMs
Standard neural networks process inputs independently. But language is sequential — the meaning of a word depends heavily on what came before it. RNNs were designed to process text one word at a time while maintaining a “memory” of previous words. LSTMs (Long Short-Term Memory networks) improved on RNNs by being able to remember relevant context over much longer distances in a text — crucial for understanding long paragraphs and documents.
Stemming & Lemmatisation — Getting to the Root
The words “run”, “running”, “ran”, and “runs” all refer to the same action. Stemming and lemmatisation are techniques that reduce inflected words to their base forms so the system treats these as variations of the same concept rather than four separate unrelated words. This massively improves the efficiency of vocabulary-based systems.
Words like “the”, “a”, “is”, “and”, and “of” appear extremely frequently in English but carry almost no meaningful information on their own. NLP systems often remove these “stop words” early in the pipeline — reducing the vocabulary the model needs to handle and allowing it to focus its attention on the words that actually carry meaning.
Transformers & Large Language Models — The Current Revolution
If NLP’s history is a long mountain climb, the Transformer architecture was the helicopter that landed on the summit in 2017. Nothing before or since has changed the field as dramatically — and everything we call “AI” today, from ChatGPT to Google Gemini, runs on Transformer-based technology.
Before Transformers, NLP systems processed text one word at a time — like reading a sentence letter by letter. Transformers introduced the attention mechanism, which allows a model to consider all words in a sentence simultaneously and weigh how much each word is relevant to understanding every other word. This seemingly simple change had profound consequences for the quality of language understanding achievable.
When you read “The trophy didn’t fit in the bag because it was too big,” you instantly know “it” refers to “the trophy,” not “the bag.” You attended to the right word based on context. The attention mechanism teaches AI to do this mathematically — for every word, calculating which other words in the sentence are most relevant to understanding it correctly.
Key Transformer-Based Models
| Model | Creator | Key Innovation | Notable Application |
|---|---|---|---|
| BERT | Google (2018) | Bidirectional training — reads text both left-to-right AND right-to-left | Google Search improvements |
| GPT-3 / GPT-4 | OpenAI (2020–2023) | Generative pre-training at massive scale; 175B+ parameters | ChatGPT, Copilot |
| T5 | Google (2019) | Framed every NLP task as text-to-text conversion | Google Translate, summarisation |
| LLaMA 2/3 | Meta (2023–2024) | Open-source LLM enabling community research and fine-tuning | Academic and enterprise NLP |
| Gemini | Google (2023–2024) | Multimodal: understands text, images, audio, and video together | Google Assistant, Workspace AI |
| Claude | Anthropic (2023–2026) | Constitutional AI training for safer, more reliable responses | Enterprise productivity, coding |
Language is the most distinctly human thing we do. Building machines that genuinely understand it is not just an engineering goal — it is one of the deepest challenges in the history of science.
— Synthesised from NLP research community, 2024NLP You Already Use Every Day
NLP is not something that exists only in research labs. You encounter it dozens of times every single day — every time you talk to your phone, type a message, perform a web search, or open your email. It has quietly become part of the fabric of modern digital life.
Voice Assistants
Siri, Google Assistant, Alexa, and Cortana all use NLP to convert your spoken words into text, understand your intent, and generate a helpful spoken response — all in under a second.
Search Engines
Google processes 8.5 billion searches per day. NLP helps it understand not just the words in your query but your intent — distinguishing “python” the programming language from “python” the snake based on context.
Email Spam Filters
Your email provider scans every incoming message using NLP models trained to recognise patterns common in spam. Modern filters catch over 99.9% of spam while rarely misclassifying genuine email.
Autocomplete & Autocorrect
The keyboard on your phone predicts your next word and fixes your typos using a compact NLP model that has learned the statistical patterns of billions of typed messages.
Language Translation
Google Translate, DeepL, and Microsoft Translator convert text between hundreds of language pairs in real time, enabling global communication at a scale that would have been unimaginable twenty years ago.
Customer Service Chatbots
The chat window that pops up when you visit a website is almost certainly powered by NLP. These bots understand your question, look up relevant information, and respond in natural language — 24 hours a day.
NLP Across Industries — Where It Changes Lives
The reach of NLP extends far beyond consumer devices. In boardrooms, hospitals, courtrooms, laboratories, and newsrooms around the world, NLP is reshaping how entire industries handle information, communicate, and make decisions.
Healthcare
NLP extracts structured information from unstructured doctor’s notes, discharge summaries, and medical literature. It powers clinical decision support tools that flag potential drug interactions, assist with diagnostic coding, and help researchers sift through millions of research papers to find relevant findings. Epic Systems and other electronic health record platforms now embed NLP throughout their workflows.
Legal
Legal teams use NLP to review thousands of contracts in hours — automatically flagging unusual clauses, identifying compliance risks, and comparing agreements against standard templates. Document discovery processes that once required weeks of lawyer time are compressed into minutes.
Finance
Investment banks run NLP sentiment analysis on news articles, earnings call transcripts, and social media to detect market-moving signals before they are widely recognised. Fraud detection systems analyse the language patterns in customer communications to identify suspicious activity in real time.
Media & Journalism
News organisations use NLP to automatically tag and categorise thousands of articles per day, detect plagiarism, monitor how their stories are spreading and being discussed on social media, and even draft initial versions of routine reports such as earnings announcements or sports scores.
Retail & E-commerce
Amazon, Flipkart, and other platforms use NLP to power product search, analyse customer reviews, personalise recommendations, and run chatbots that handle millions of customer queries without human agents — reducing service costs while improving response times.
Education
NLP enables automated essay grading, personalised tutoring systems that adapt to each student’s learning style, language learning apps that give real-time pronunciation feedback, and accessibility tools that transcribe lectures for students with hearing impairments.
NLP in Business — Why Companies Invest So Heavily
NLP has shifted from an interesting research curiosity to a core business capability. Companies that harness it effectively process more information, serve customers better, operate at lower cost, and make smarter decisions than those that do not.
Key Business Use Cases
- Sensitive Data Redaction: Legal, insurance, and healthcare organisations use NLP to automatically detect and mask personally identifiable information in documents — reducing compliance risk and protecting privacy at scale.
- Customer Sentiment Monitoring: Continuously scan social media, review platforms, and support tickets to understand the real-time pulse of customer opinion — enabling faster responses to emerging problems.
- Voice of the Customer Analysis: Turn call centre recordings and chat transcripts into quantified insights about product issues, feature requests, and service quality — without requiring human review of every conversation.
- Intelligent Document Processing: Extract key information (invoice amounts, dates, party names) from thousands of incoming documents automatically, eliminating manual data entry and its associated errors.
- Employee Assistance: Internal knowledge base chatbots help employees find HR policies, IT documentation, and procedural guides instantly — reducing the load on support teams.
- Competitive Intelligence: Monitor news, job postings, and public filings from competitors using NLP to detect strategic moves before they are widely reported.
Pros & Cons of Natural Language Processing
Like every powerful technology, NLP comes with genuine strengths that make it transformative — and real limitations that must be understood before deploying it. Here is an honest assessment of both sides.
✓ Advantages
- Processes massive volumes of text at speeds impossible for humans
- Works 24/7 without fatigue, breaks, or inconsistency
- Enables entirely new products (chatbots, voice assistants, translators)
- Unlocks insights from unstructured data that was previously inaccessible
- Reduces costs for repetitive language-based tasks (customer service, data entry)
- Scales instantly — handling 1 or 1 million requests costs approximately the same
- Handles multiple languages simultaneously at production scale
- Can detect subtle patterns humans would miss across large corpora
✗ Disadvantages
- Struggles with sarcasm, irony, humour, and figurative language
- Can inherit and amplify biases present in training data
- Lower accuracy on rare languages and dialects
- Context can still confuse even the best models in edge cases
- Deep learning models are “black boxes” — hard to explain decisions
- Requires enormous training data and compute resources
- Privacy risks when processing sensitive personal text
- Can generate convincingly wrong information with false confidence
Challenges That NLP Still Struggles With
Despite remarkable progress, NLP systems are not perfect — not even close. There are specific aspects of human language that remain genuinely difficult for machines, and understanding these limitations is critical before deploying NLP in any high-stakes situation.
“Oh great, another Monday” is clearly negative — but the word “great” is positive. Context, tone, and cultural knowledge are required to understand sarcasm, and machines still regularly get it wrong.
New slang, acronyms, and cultural references emerge constantly. A model trained six months ago may not understand today’s newest internet slang or current events references.
Maintaining coherence across a very long document — understanding how page 1 affects the meaning of page 50 — remains challenging even for powerful transformer models with large context windows.
NLP models need vast amounts of text data to train. For most of the world’s 7,000 languages — especially indigenous and regional ones — this data simply does not exist. NLP remains dramatically better for English and a handful of other major languages.
“Can you pass the salt?” is grammatically a question about ability — but pragmatically it is a polite request. Understanding the social intent behind language, not just its literal meaning, remains an open research challenge.
Language models are trained on text, not mathematics. They often perform poorly on tasks requiring precise arithmetic, logical inference, or multi-step numerical reasoning — areas where traditional calculators outperform them easily.
Ethics & Bias in NLP — The Hidden Risks
The most sophisticated NLP system is only as fair and trustworthy as the data it learned from. If that data reflects the biases, prejudices, and imbalances of the world it was collected from — and it always does, to some degree — the system will reproduce and amplify those same biases at scale.
A landmark example: early word embedding models learned that “doctor” was more closely associated with “man” than with “woman” — simply because the training text (written by humans in a world where medicine was historically male-dominated) contained that pattern. The model did not “decide” to be sexist; it faithfully learned the statistics of human-produced text. But the consequences of deploying such a model in hiring, medical diagnosis, or legal contexts could be severely unjust.
Representational Bias
When training data over-represents some groups (wealthy, English-speaking, urban) and under-represents others (rural, non-English, elderly), the model performs better for the majority group and worse for minority groups — amplifying existing inequalities.
Hallucination
Large language models sometimes generate completely false statements with apparent confidence — “hallucinating” plausible-sounding but incorrect information. In legal, medical, or journalistic contexts, this is a serious and potentially dangerous failure mode.
Privacy
NLP systems trained on internet text may have memorised sensitive personal information that appears in their outputs. Systems that process medical, legal, or financial documents face strict obligations about how that language is stored, processed, and protected.
Leading AI organisations are addressing these challenges through bias auditing (systematically testing for unequal performance across demographic groups), diverse and representative training data curation, transparency about model limitations, human-in-the-loop systems for high-stakes decisions, and regulatory compliance frameworks. The goal is NLP systems that are not just powerful, but fair, transparent, and trustworthy.
The Future of NLP — Where Are We Headed?
NLP has changed more in the last five years than in the previous fifty. And the pace of change is not slowing — it is accelerating. Here are the most significant directions in which NLP is evolving right now.
Multimodal NLP
The next generation of NLP systems do not just process text — they simultaneously understand images, audio, video, and code alongside language. Google’s Gemini and OpenAI’s GPT-4V are early examples of this convergence, enabling entirely new kinds of interactions like describing what is happening in a photograph or answering questions about a video.
Low-Resource Language NLP
Researchers are developing techniques to build effective NLP systems even for languages with very little training data — using transfer learning (adapting knowledge from high-resource languages) and multilingual models that share linguistic knowledge across many languages simultaneously.
Scientific NLP
NLP models trained on scientific literature are accelerating drug discovery, materials science research, and genomics. AlphaFold’s success in predicting protein structures inspired a wave of AI systems that treat biological sequences as a kind of language — opening entirely new research possibilities.
Conversational AI Agents
Future NLP systems will move beyond answering single questions to participating in extended, goal-oriented conversations — booking appointments, managing complex workflows, collaborating on creative projects, and operating as autonomous agents that take real-world actions on behalf of their users.
Future NLP systems will adapt not just to the content of a conversation but to the individual user’s vocabulary, expertise level, emotional state, and communication style — in real time. A doctor asking about a medication will receive a clinical-level response; a patient asking the same question will receive a clear, jargon-free explanation. This contextual personalisation represents the next major leap in human-computer communication.
Popular NLP Tools, Libraries & Platforms
Whether you are a researcher, a software engineer, or a business leader, a rich ecosystem of NLP tools is available — from low-level Python libraries for building custom models from scratch to fully managed cloud services requiring no machine learning expertise at all.
| Tool / Library | Type | Best For | Organisation |
|---|---|---|---|
| NLTK | Python library | Learning NLP, academic research, classical techniques | Open Source |
| spaCy | Python library | Fast, production-grade NLP pipelines (NER, POS, parsing) | Explosion AI |
| Hugging Face Transformers | Python library | State-of-the-art pre-trained models (BERT, GPT, T5 etc.) | Hugging Face |
| Gensim | Python library | Topic modelling, word embeddings (Word2Vec, Doc2Vec) | Open Source |
| Stanford CoreNLP | Java / API | Full linguistic analysis pipeline; academic research | Stanford NLP Group |
| Amazon Comprehend | Cloud API | Managed NLP for sentiment, entities, key phrases — no ML needed | Amazon Web Services |
| Google Cloud Natural Language | Cloud API | Managed NLP service for text analysis, classification, sentiment | Google Cloud |
| IBM Watson NLP | Cloud platform | Enterprise NLP with explainability and governance features | IBM |
| Azure Cognitive Services (Language) | Cloud API | Managed NLP for Azure users; integrates with Office 365 | Microsoft |
| OpenAI API | Cloud API | Access to GPT-4 and other LLMs for any NLP task via prompt | OpenAI |
The NLP Stack by Experience Level
Beginner
Start with NLTK for learning core concepts, then explore spaCy for practical exercises. Use Google Colab (free cloud Python environment) to run experiments without setting anything up locally.
Intermediate
Move to Hugging Face Transformers to work with pre-trained BERT and GPT-style models. Learn fine-tuning to adapt these models to specific tasks using your own labelled data.
Production / Enterprise
Use cloud NLP APIs (AWS Comprehend, Google Cloud NL, Azure Language) for fast deployment without model management. For custom requirements, combine Hugging Face models with FastAPI and containerise for Kubernetes deployment.
Key Terms Glossary
| Term | Plain-English Meaning |
|---|---|
| Attention Mechanism | A technique that helps a model focus on the most relevant parts of a sentence when processing each word |
| Corpus | A large collection of text used for training or evaluating NLP models |
| Embedding | A mathematical representation of a word or sentence as a list of numbers that captures meaning |
| Fine-tuning | Further training a pre-trained model on a specific smaller dataset to adapt it for a specific task |
| Hallucination | When an AI confidently generates false or fabricated information that sounds plausible |
| Lemmatisation | Reducing a word to its base dictionary form (e.g., “running” → “run”, “better” → “good”) |
| LLM (Large Language Model) | A very large neural network trained on vast text data that can perform almost any language task |
| NER (Named Entity Recognition) | The task of identifying and categorising named entities (people, places, organisations) in text |
| NLG (Natural Language Generation) | The sub-field of NLP focused on producing coherent, meaningful text from data or intent |
| NLU (Natural Language Understanding) | The sub-field focused on comprehending the meaning and intent behind human language |
| POS Tagging | Part-of-speech tagging — labelling each word as a noun, verb, adjective, etc. |
| Pre-training | Training a model on a massive general dataset before fine-tuning it for a specific task |
| Sentiment Analysis | Determining whether a piece of text expresses positive, negative, or neutral emotion |
| Stemming | Crudely reducing a word to its root by stripping suffixes (e.g., “playing” → “play”) |
| Stop Words | Common words (the, a, is, of) that are often removed because they carry little meaningful information |
| Tokenisation | Splitting text into individual units (words, sub-words, characters) that a model can process |
| Transformer | A neural network architecture using attention mechanisms that underpins virtually all modern NLP models |
| Word2Vec | A technique for creating word embeddings — converting words into vectors of numbers that capture meaning |
Sources & Further Reading
This document was synthesised from the following primary references, supplemented with additional research from published academic papers and industry documentation.
IBM’s comprehensive explainer covering NLP definitions, techniques, and enterprise applications.
Andrew Ng’s team’s thorough guide covering 11 NLP tasks, deep learning approaches, and model architectures.
Amazon’s technical overview covering NLP use cases, approaches (supervised, unsupervised, NLU, NLG), and core tasks.
Beginner-accessible article covering NLP definition, techniques, benefits, limitations, and tools including Python libraries.
Detailed technical breakdown of NLP mechanics, NLU vs NLG, benefits, challenges, and industry examples.
Comprehensive practical guide covering NLP concepts, techniques, and Python toolkits for beginners entering the field.
Microsoft’s perspective on NLP fundamentals, how Copilot and modern AI assistants use NLP, and real-world applications.
In-depth coverage of NLP fundamentals, linguistic foundations, NLU/NLG distinction, and code-level examples.
Business-focused overview of NLP capabilities, deployment considerations, and automated ML approaches.
Data integration perspective on NLP, covering how unstructured text data feeds into NLP pipelines and business analytics.