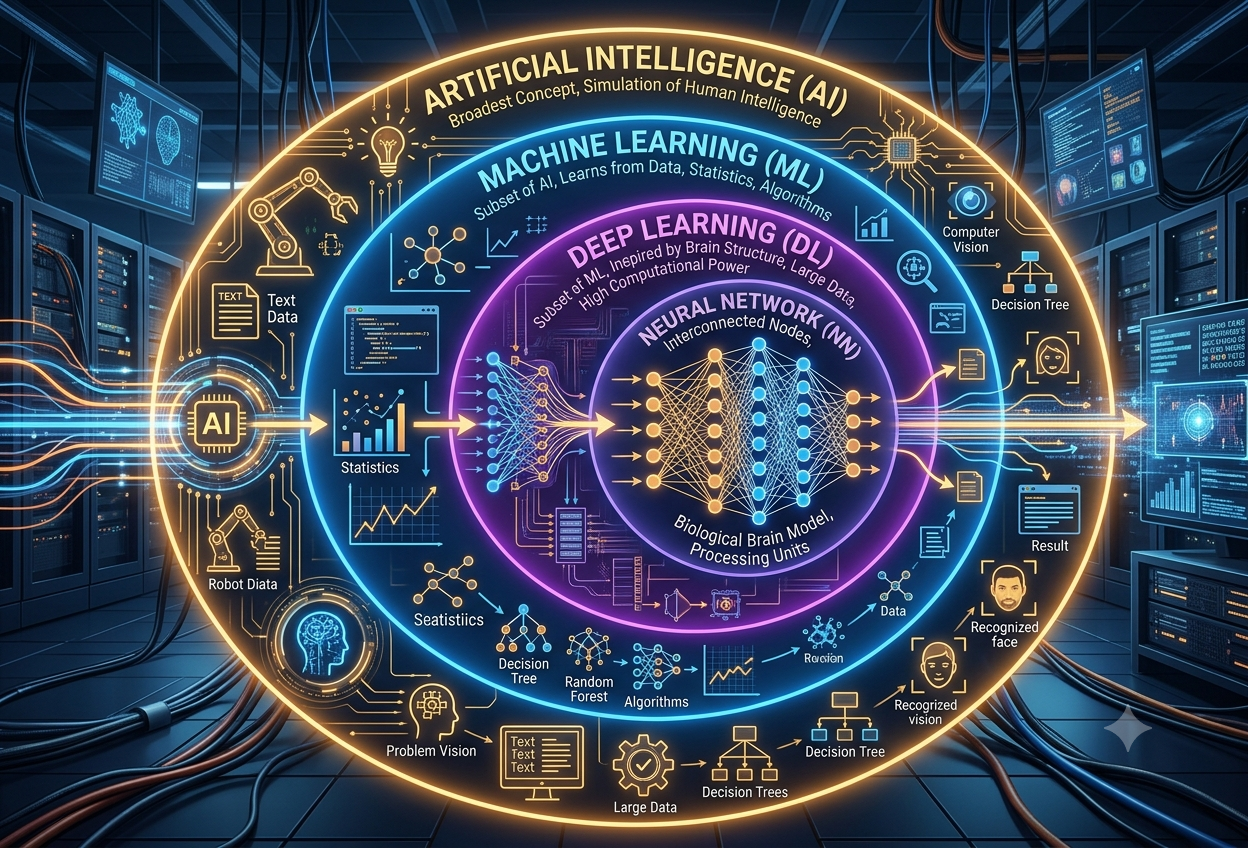
AI vs Machine Learning vs Deep Learning
Why These Terms Get Confused
Artificial Intelligence, Machine Learning, Deep Learning, Neural Networks, and Generative AI are not interchangeable synonyms. They represent a precise conceptual hierarchy — each term is a subset of the one before it.
In boardrooms, media headlines, and casual conversation, these five terms are routinely used as if they mean the same thing. A company announces it uses “AI” when it really uses a linear regression model. A journalist writes “deep learning” when describing a rules-based chatbot. This confusion carries real cost: misaligned expectations, bad procurement decisions, and failed projects.
This reference cuts through the ambiguity. Drawing on IBM Research, Google Cloud, IIT Kanpur (EICTA), Coursera, freeCodeCamp, GeeksforGeeks, and Simplilearn, it builds a complete picture of what each term actually means — from first principles to production use cases.
AI is the broad goal (machines that think); Machine Learning is a method to achieve AI (learning from data); Deep Learning is an ML technique (using layered neural networks); Neural Networks are the architecture that powers Deep Learning; and Generative AI is the most advanced application — systems that create entirely new content.
The Nesting Hierarchy
Think of these technologies as concentric circles — each inner circle is a more specialised, more powerful, and more data-hungry version of the outer circle that contains it.
The Containment Relationship Explained
IBM’s Data and AI team offers the clearest mental model: think of AI, ML, deep learning, and neural networks as a series of systems from largest to smallest, each encompassing the next. AI is the overarching umbrella concept. Machine Learning is one specific — but enormously powerful — approach to implementing AI. Deep Learning is a particular family of ML techniques that relies on layered neural networks. Neural Networks are the computational architecture that Deep Learning is built upon. Generative AI is the frontier application of the deepest neural networks, focused on creating new content rather than merely classifying existing data.
Any technique that lets machines mimic human cognitive functions.
The umbrella that contains everything below.
Systems that learn patterns from data instead of following hand-written rules.
One way to achieve AI — currently the dominant one.
ML that uses many-layered neural networks to learn hierarchical representations automatically.
The most powerful — and data-hungry — class of ML.
Interconnected layers of artificial neurons inspired by the biological brain.
The engine that makes Deep Learning possible.
Deep models that generate entirely new content — text, images, audio, code.
The frontier application built on everything above.
All Deep Learning is Machine Learning, but not all Machine Learning is Deep Learning. All Machine Learning is AI, but not all AI is Machine Learning. You can have AI without any ML at all — rule-based expert systems from the 1980s were genuine AI with zero learning from data.
Artificial Intelligence
AI is the broadest possible framing: any technique that enables a computer to mimic cognitive functions associated with human minds — learning, reasoning, problem-solving, perception, and language understanding.
“The theory and development of computer systems able to perform tasks that normally require human intelligence, such as visual perception, speech recognition, decision-making, and translation between languages.”— Oxford Languages / Encyclopaedia Britannica
What AI Is — and Isn’t
AI encompasses an enormous range of techniques — from hand-crafted rules and logical inference to statistical learning and deep neural networks. The unifying thread is the goal: behaviour that, if exhibited by a human, we would call intelligent. A chess engine, a spam filter, a medical diagnosis system, and a language model are all AI — even though they work in completely different ways.
AI does not require learning. A rule-based system that follows thousands of hard-coded IF-THEN rules to diagnose a disease is AI. A symbolic planner that searches a game tree for the best move is AI. Only some AI systems actually learn from data — those are Machine Learning systems.
The Three Categories of AI
Performs one specific task — often better than any human. Examples: chess engines, spam detectors, image classifiers, recommendation engines, voice assistants. All current commercial AI is ANI.
Exists NowWould perform any cognitive task a human can — reasoning, learning, and planning across all domains. Researchers actively debate whether current LLMs approach AGI in limited senses.
Not YetWould surpass the smartest humans in every field — creativity, social skills, strategic planning, and scientific discovery. Discussed in AI safety research. Does not currently exist.
TheoreticalAI Approaches: A Taxonomy
- Symbolic AI / Expert Systems: Encode human knowledge as rules and logical relationships. Dominated AI research from the 1960s–1980s. IBM’s Deep Blue used symbolic search to defeat Kasparov in 1997.
- Search and Planning: Systematically explore solution spaces. Used in game-playing (minimax, MCTS), logistics optimisation, and robotics path planning.
- Probabilistic / Bayesian AI: Reason under uncertainty using probability theory. Used in spam filters, medical diagnostics, sensor fusion, and autonomous driving decision-making.
- Machine Learning: Learn patterns from data without being explicitly programmed. The dominant paradigm since the 2010s. Includes classical ML and deep learning.
- Evolutionary Algorithms: Optimise solutions by simulating natural selection. Used in engineering design, hyperparameter optimisation, and neural architecture search.
- Reinforcement Learning: Learn by trial-and-error interaction with an environment. Powers game agents (AlphaGo, OpenAI Five), robotics, and recommendation systems.
- Natural Language Processing: Parse, understand, and generate human language — from rule-based parsers to modern Transformer-based LLMs.
Approximately 35% of companies globally have adopted AI in at least one business function, and another 42% are actively exploring it. IBM research showed generative AI accelerating time-to-value by up to 70% faster than traditional AI implementations. The global AI market is projected to exceed $1.3 trillion by 2030. Over 80% of organisational data is estimated to be unstructured — the domain where deep learning excels.
Machine Learning
Machine Learning is the subset of AI where systems learn from data — improving their performance on a task through experience rather than through explicit programming for every scenario.
“Machine learning is a subset of AI that enables a system to autonomously learn and improve without being explicitly programmed. Algorithms recognise patterns in data and make predictions when new data is input.”— Google Cloud
The Core Idea: Learning from Examples
The key distinction from traditional programming is elegant: instead of a human writing rules (“if the email contains ‘FREE MONEY’ and has more than 3 exclamation marks, mark it as spam”), you feed the system thousands of examples and let it figure out the rules itself. The rules discovered by data are often more nuanced and accurate than anything a human would write.
Arthur Samuel, who coined the term in 1959, defined ML as giving computers “the ability to learn without being explicitly programmed.” A well-trained ML model will generalise — performing accurately on data it has never seen before.
The Machine Learning Workflow
Data Collection
Gather large volumes of examples — emails, images, transactions, sensor readings. Quality and quantity of data are the primary determinants of model performance.
Data Preparation & Preprocessing
Clean missing values, remove duplicates, normalise numerical features, encode categorical variables. This step consumes 60–80% of a data scientist’s project time.
Feature Engineering
In classical ML, humans must explicitly construct the input variables (features). For house price prediction: extract “age of building,” “distance to metro,” “floor area” from raw data. Deep learning replaces this step with automatic learning.
Algorithm Selection & Training
Choose the right model family, then train by iteratively adjusting internal parameters to minimise prediction error. May take seconds (linear regression) to hours (gradient boosting on large datasets).
Evaluation
Test on held-out data the model has never seen. Measure accuracy, precision, recall, F1, AUC-ROC, or RMSE depending on the task. Watch for overfitting — where the model memorises training data but fails on new examples.
Deployment & Monitoring
Serve the model via APIs, embed it in applications, or run batch inference. Monitor for data drift — when distribution shifts, model performance degrades and retraining is needed.
Key Characteristics of Machine Learning
- Data-driven performance: Model quality is determined by data quality and volume, not the programmer’s domain expertise.
- Generalisation: A well-trained model performs accurately on unseen data — this is the entire point of ML.
- Feature Engineering Required (Classical ML): Humans must construct meaningful input variables from raw data.
- Interpretability Range: Decision trees and linear models are highly interpretable; ensemble methods are moderately so.
- Modest Compute Needs: Most classical ML runs efficiently on standard CPUs — no GPU required.
- Structured Data Friendly: ML excels with tabular data. Raw unstructured data (images, audio) requires Deep Learning.
- Performance Ceiling: Classical ML performance often plateaus with more data. Deep learning continues to improve with scale.
Deep Learning
Deep Learning is a specialised subset of Machine Learning that uses artificial neural networks with many hidden layers to automatically learn hierarchical representations from raw data — no manual feature engineering required.
“Deep learning uses artificial neural networks to process and analyse information. It is particularly powerful for analysing large amounts of unstructured data and is used in image recognition, speech processing, and natural language understanding.”— Google Cloud
Why “Deep”?
The “deep” in Deep Learning refers to the depth of the neural network — the number of layers stacked between input and output. A network with one or two hidden layers is shallow. A network with many hidden layers (often dozens or hundreds in modern systems) is “deep.” This depth gives the model capacity to learn increasingly abstract representations of data.
A deep network processing an image learns in its first layers to detect edges, in middle layers to combine edges into shapes and textures, and in its final layers to identify high-level objects like “face,” “car,” or “dog.” No human programmer specifies this hierarchy — it emerges automatically from training on millions of labelled examples.
Deep Learning vs Machine Learning — Critical Differences
| Dimension | Machine Learning | Deep Learning |
|---|---|---|
| Feature Engineering | Manual — human experts craft features | Automatic — network learns features from raw data |
| Data Volume | Moderate — thousands to hundreds of thousands | Large — millions of examples typically required |
| Hardware | Standard CPU usually sufficient | GPU/TPU practically required for training |
| Training Time | Seconds to hours | Hours to weeks (large models) |
| Interpretability | Higher (decision trees, linear models) | Lower — “black box” challenge |
| Structured Data | Excellent (gradient boosting often wins) | Not always an improvement |
| Unstructured Data | Poor without manual feature engineering | State-of-the-art performance |
| Correlation Type | Primarily linear correlations | Non-linear, complex, hierarchical correlations |
| Scalability with Data | Performance plateaus | Continues improving with more data and compute |
Deep learning is sometimes called “scalable machine learning.” Unlike traditional ML algorithms whose performance plateaus with more data, deep learning models typically continue to improve as more data and compute are added — which is why the largest AI companies invest billions in GPU clusters.
Neural Networks
A neural network is the computational architecture that makes deep learning possible. Inspired by biological neurons in the human brain, artificial neural networks are systems of interconnected nodes that process information in parallel, learning to recognise patterns through exposure to examples.
“A neural network is a machine learning method modelled on the human brain. It consists of layers of interconnected nodes (neurons) that process inputs using weighted connections and activation functions to produce an output — learning by adjusting weights through backpropagation.”— Synthesised from Google Cloud, IBM, and academic sources
Anatomy of a Neural Network
The basic unit. Receives weighted inputs, adds a bias, then passes the result through an activation function — analogous to a biological neuron receiving signals from dendrites.
Learned parameters. Weights determine connection strength; bias allows activation even when inputs are zero. Training adjusts these values to reduce error.
ReLU, Sigmoid, Tanh — introduce non-linearity so the network can learn complex curved decision boundaries. Without them, a 100-layer network collapses into one linear transformation.
Receives raw features — pixel values, token embeddings, sensor readings. One neuron per input feature; no computation occurs here.
The intermediate layers between input and output. Each learns increasingly abstract representations. 3+ hidden layers makes a network formally “deep.”
Produces the final prediction — a sigmoid neuron for binary classification, softmax over N neurons for multi-class, linear for regression.
Quantifies how wrong the network’s predictions are versus ground truth — Cross-Entropy (classification), MSE (regression). The optimiser’s job is to minimise this value.
The chain-rule calculus that computes how much each weight contributed to the total error — enabling gradient descent to update every weight in the network simultaneously.
Each neuron computes: output = activation(Σ(weight × input) + bias). Backpropagation calculates ∂Loss/∂weight for every weight simultaneously using the chain rule. An optimiser (SGD, Adam, AdaGrad) then nudges each weight slightly in the direction that reduces loss. Repeat for millions of examples over many epochs — and the network learns.
Shallow vs Deep — What “Depth” Actually Means
The term “deep” simply refers to the number of layers. A network with one hidden layer is “shallow” — sufficient for some tasks but limited. Networks with 3+ hidden layers are considered “deep.” Modern production models dwarf this minimum: GPT-4 has an estimated 96+ transformer layers; ResNet-152 has 152 convolutional layers; AlphaFold 2 uses 48 Evoformer blocks.
Generative AI
Generative AI is the branch of deep learning focused not on classifying or predicting from existing data — but on creating entirely new content: text, images, audio, video, code, and molecules. It represents the most visible and commercially transformative wave of AI since the 2012 deep learning breakthrough.
Traditional AI/ML/DL answers questions: “Is this email spam? What will this stock price be?” Generative AI creates answers: “Write me an email. Generate a product image. Compose a piece of music.” The shift from discriminative to generative modelling is profound — it moves AI from analytical tool to creative collaborator.
Six Major Classes of Generative AI
Transformer-based models trained on hundreds of billions of tokens. Generate coherent language for writing, coding, reasoning, translation. Examples: GPT-4, Claude, Gemini, Llama 3, Mistral.
LiveLearn to reverse a noise-corruption process, gradually denoising random pixels into photorealistic images or video. Examples: Stable Diffusion, DALL·E 3, Midjourney, Sora.
LiveGenerate realistic speech, clone voices, compose music, or produce sound effects from descriptions. Examples: ElevenLabs, Suno AI, Udio, Voicebox.
LiveLLMs fine-tuned on code repositories that can write, explain, debug, and refactor code across dozens of languages. Examples: GitHub Copilot, Claude Code, Cursor, Replit AI.
LiveAccept and generate across text, images, audio, and video within a single model. Examples: GPT-4o, Gemini 1.5, Claude 3 — can describe images, answer questions about video.
FrontierGenerative models trained on biological and chemical data that propose novel protein structures, drug molecules, and materials. Examples: AlphaFold 3, RFdiffusion, MolDiff.
ResearchKey Architectures Behind Generative AI
| Architecture | Core Mechanism | Best For | Examples |
|---|---|---|---|
| Transformer | Self-attention over token sequences; parallel processing of all positions | Text, code, multimodal reasoning | GPT-4, Claude, Gemini, BERT |
| Diffusion Model | Learns to reverse Gaussian noise addition (denoising score matching) | Images, video, audio | Stable Diffusion, DALL·E 3, Sora |
| GAN | Generator vs discriminator adversarial training loop | Photorealistic faces, image style transfer | StyleGAN3, CycleGAN, Pix2Pix |
| VAE | Encodes inputs to latent distribution; decodes samples back to data space | Smooth interpolation, anomaly detection, latent representation | VQ-VAE-2, Stable Diffusion’s latent encoder |
| Flow Models | Exact invertible transformations; tractable likelihood computation | Density estimation, lossless generative modelling | Glow, RealNVP, Flow Matching |
| State Space Models | Linear recurrence with structured state transition matrices | Long sequences, audio, genomics | Mamba, S4, Hyena |
“The arrival of ChatGPT in November 2022 triggered a global reckoning with AI capability. Within 5 days it reached 1 million users. Within 2 months, 100 million. No consumer technology in history reached mass adoption faster.”
— Industry analysis, 2023Reinforcement Learning from Human Feedback (RLHF) is the secret weapon behind ChatGPT, Claude, and Gemini. After pre-training on internet text, models are fine-tuned using (1) Supervised Fine-Tuning on human-written ideal responses, (2) Reward Model Training where humans rank model outputs, and (3) PPO to push the LLM toward outputs the reward model rates highly. The result: models that are helpful, harmless, and honest rather than merely statistically plausible.
Machine Learning Algorithm Types
Machine learning is not a single algorithm but a family of learning paradigms, each suited to different data situations. Understanding when data is labelled vs unlabelled, static vs interactive, is the key to choosing the right approach.
The Four Major Learning Paradigms
Labelled training data — input/output pairs. The model learns a mapping function from examples. Gold standard when labelled data is available.
No labels — model discovers hidden structure, clusters, or patterns in data. Crucial when labelling is expensive or impossible.
Small labelled dataset + large unlabelled pool. Leverages structure in unlabelled data to improve performance beyond labelled examples alone.
An agent takes actions in an environment, receives reward/penalty signals, and learns a policy to maximise cumulative reward over time.
Supervised Learning — Algorithm Families
| Family | Key Algorithms | Best For | Strengths |
|---|---|---|---|
| Linear Models | Linear/Logistic Regression, Ridge, Lasso, ElasticNet | Numerical prediction, binary classification, baseline | Fast, interpretable, works with small data |
| Tree-Based | Decision Trees, Random Forest, XGBoost, LightGBM, CatBoost | Tabular data, structured features | Handles non-linearity, mixed types, feature importance |
| Support Vector Machines | SVM, SVR, Kernel SVM | Classification with clear margin, text classification | Effective in high dimensions, kernel trick |
| Instance-Based | k-NN, Locally Weighted Regression | Low-dimensional data, prototyping | Simple, no training phase, multi-class friendly |
| Probabilistic | Naive Bayes, Gaussian Process, Bayesian Networks | Text classification, uncertainty quantification | Built-in uncertainty, works with small data |
| Neural Networks | MLP, CNN, RNN, Transformer | Images, text, sequences, complex patterns | Universal approximator, state-of-the-art on unstructured data |
Unsupervised Learning — Algorithm Families
| Task | Key Algorithms | Typical Application |
|---|---|---|
| Clustering | k-Means, DBSCAN, Hierarchical, Gaussian Mixture Models | Customer segmentation, document grouping, anomaly detection |
| Dimensionality Reduction | PCA, t-SNE, UMAP, Autoencoders | Visualisation, feature compression, noise removal |
| Generative Modelling | GANs, VAEs, Diffusion, Flow Models | Image synthesis, data augmentation, anomaly detection |
| Association Rules | Apriori, FP-Growth, Eclat | Market basket analysis, recommendation rules |
| Self-Supervised | Contrastive (SimCLR, CLIP), BERT masked LM | Pre-training on unlabelled data for later fine-tuning |
RL has produced AI’s most dramatic results: AlphaGo (2016) defeated the world Go champion; AlphaZero (2017) mastered Chess, Shogi, and Go from scratch in 24 hours; OpenAI Five (2019) beat professional Dota 2 teams; AlphaFold 2 (2020) solved the 50-year protein folding problem. Modern LLMs use RL (via RLHF) to align behaviour with human preferences.
Neural Network Architectures
Just as there are many ML algorithm families, neural networks come in a rich variety of architectures — each shaped by the structure of the data it was designed for. Understanding which architecture fits which problem is a core skill for any AI practitioner.
Feedforward NN / MLP
The simplest architecture — data flows in one direction from input to output through fully connected layers. Foundation for all other architectures. Best for structured tabular data, basic classification and regression.
CNN (Convolutional)
Uses sliding filter kernels to detect local spatial patterns — edges, textures, shapes — that translate regardless of position. Dominant architecture for images, video, and any data with local spatial structure.
RNN (Recurrent)
Maintains a hidden state that carries information across time steps, enabling sequential data processing. Used for text, time series, speech. Suffers from vanishing gradient — limited long-range memory.
LSTM
Adds input, forget, and output gates to the recurrent cell — enabling selective memory over long sequences. Pre-Transformer standard for NLP, speech recognition, and time-series forecasting.
GAN
Two networks trained in opposition: a Generator creating fake samples, a Discriminator judging real vs fake. Competition drives the generator to produce increasingly realistic outputs.
Autoencoder / VAE
Encoder compresses data to a low-dimensional latent representation; decoder reconstructs the original. VAEs add probabilistic structure to the latent space.
Transformer
Self-attention allows every token to attend to every other token simultaneously — capturing long-range dependencies that RNNs struggled with. Backbone of all modern LLMs and vision transformers (ViT).
Diffusion Model
Trains by adding Gaussian noise incrementally, then learning the reverse process (denoising). At inference, starts from pure noise and denoises to a coherent output guided by text or other conditioning.
Graph Neural Network
Operates on graph-structured data — nodes and edges. Each node aggregates information from its neighbours iteratively. Applied to social networks, molecular property prediction, chip design.
State Space Models
Linear recurrence with structured transition matrices. Efficient alternative to Transformers for very long sequences — Mamba, S4, Hyena.
Tabular/structured data: MLP or gradient boosting first. Images: CNN or Vision Transformer. Text/sequences: Transformer. Long sequences with limited compute: LSTM or State Space Model (Mamba). Image generation: Diffusion Model. Graphs/molecules: GNN. Anomaly detection: Autoencoder or VAE. Time series: Temporal CNN, LSTM, or Transformer depending on length.
Feature Engineering — Manual vs Automatic
One of the starkest distinctions between classical machine learning and deep learning is who does the feature engineering. This single difference has enormous practical consequences for the skills required, the data needed, and the performance achievable.
Images, text, sensor logs, transactions.
Same raw inputs — no pre-extraction required.
👨💻 Human expert manually crafts domain-specific features (age, ratios, text frequencies, edge histograms).
🤖 Network learns its own features — Layer 1→2→3 builds progressively abstract representations.
Hand-engineered feature vector.
Learned latent representation, end-to-end optimised.
SVM, Random Forest, XGBoost, Logistic Regression.
CNN, RNN, Transformer — output layer for classification or generation.
🚧 Feature quality = model quality. Bottleneck is human expertise.
✅ Scales with data & compute. No domain expertise required.
Automatic feature learning is not universally superior. For small, structured datasets (thousands of rows, well-defined columns), hand-crafted features combined with gradient boosting still frequently outperform deep learning. The advantage of automatic feature learning only manifests reliably with large volumes of raw, unstructured data.
Head-to-Head Comparison
The definitive reference table — comparing Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI across every meaningful dimension in one place.
| Dimension | AI | ML | DL | GenAI |
|---|---|---|---|---|
| Definition | Simulation of human intelligence | Systems that learn from data | ML using deep neural networks | DL models that create new content |
| Relationship | Broadest field | Subset of AI | Subset of ML | Subset of DL |
| Origin | 1956 — Dartmouth | 1959 — Arthur Samuel | 2012 — AlexNet | 2014 GANs / 2017 Transformers / 2022 ChatGPT |
| Primary Goal | Human-level problem solving | Learn predictive patterns | Automatic feature extraction | Create new contextually appropriate content |
| Feature Engineering | Varies | Mostly manual | Fully automatic | Fully automatic (pre-trained) |
| Data Requirements | Varies widely | Thousands to hundreds of thousands | Millions of examples | Billions of tokens / millions of images |
| Hardware | CPU to GPU cluster | Typically CPU | GPU/TPU required | Large GPU/TPU clusters |
| Interpretability | High to very low | Medium | Low — black box | Very low |
| Best Data Type | Structured + unstructured | Structured / tabular | Unstructured | Large-scale multimodal |
| Scalability | Limited to high | Plateaus | Improves with data and compute | Extreme — trillion-parameter models |
| Key Algorithms | Rules, search, all ML | Linear, SVM, Random Forest, XGBoost | CNN, RNN, LSTM, Transformer, GAN, Diffusion | GPT, Stable Diffusion, DALL·E, Sora, Claude |
| Output Type | Decision, classification, text, action | Prediction, probability, cluster | Classification, detection, translation | Generated text, image, audio, video, code |
| Example Apps | Chess engines, voice assistants | Spam filters, credit scoring, churn prediction | Speech-to-text, image recognition, self-driving | ChatGPT, Copilot, DALL·E, Sora, Midjourney |
When to Use What
Choosing the right approach is a practitioner skill. The “most powerful” technique is not always the right one. Here is a decision framework for matching AI approach to real-world problem characteristics.
✅ Small-to-medium dataset (under 100K rows)
✅ Structured / tabular data with meaningful columns
✅ Interpretability legally or operationally required
✅ Training compute is limited
✅ Fast iteration and prototyping
❌ Avoid when input is raw images, audio, or long text
✅ Input is unstructured: images, audio, video, text
✅ Dataset is large (millions+ examples)
✅ State-of-the-art performance is the priority
✅ GPU/TPU compute is available
✅ End-to-end training preferred
❌ Avoid when data is scarce and explainability is required
✅ Task requires generating novel content
✅ Conversational interface needed
✅ Summarisation, translation, creative writing
✅ Budget allows API costs or fine-tuning
✅ General-purpose capability over specialised accuracy
❌ Avoid for precise numerical predictions or regulated decisions
✅ Logic is clear, fixed, and fully enumerable
✅ Zero tolerance for errors or unexpected behaviour
✅ Full auditability of every decision required
✅ Narrow, well-understood domain
✅ No training data available
❌ Avoid when problem space is large, fuzzy, or ambiguous
Start simple. A logistic regression or gradient boosting baseline is fast to build, easy to explain, and often surprisingly competitive. Graduate to deep learning when the baseline clearly plateaus and you have the data to support it. Only reach for foundation model fine-tuning when the task genuinely requires language or multimodal understanding. The best model is the simplest one that meets the performance bar.
Real-World Applications
AI, ML, and DL are no longer research topics — they are running in production, at massive scale, in systems that billions of people interact with every day. Here is where each layer of the hierarchy is doing the actual work.
Everyday AI You Use Without Knowing It
Google’s ML-based filter processes over 100M spam emails per day, blocking 99.9% before they reach inboxes. Uses Naive Bayes, logistic regression, and deep text classifiers.
LiveVisa’s AI evaluates 65,000 transactions/second, flagging fraud in under 300ms. Gradient boosting + deep learning score every transaction against hundreds of behavioural features.
LiveNetflix attributes over 80% of content viewed to its recommender. Collaborative filtering + DL surfaces what you’ll watch next — saving an estimated $1B annually in churn reduction.
LiveSiri, Alexa, Google Assistant combine deep ASR (RNN/Transformer) with NLU to transcribe speech, extract intent, and execute commands at word error rates below 5%.
LivePhone face unlock uses CNN-based detection. Photo apps automatically tag people, places, and objects with superhuman accuracy on benchmark datasets.
LiveGoogle Maps uses ML to predict traffic, estimate arrival times, and route millions of trips simultaneously — accurate to within minutes.
LiveAmazon’s recommendation engine drives ~35% of revenue. ML models predict demand, adjust pricing in real time across hundreds of millions of SKUs.
LiveGoogle Translate uses Transformer-based NMT to translate 100B+ words/day across 133 languages. The 2016 shift to neural MT exceeded the prior decade of research combined.
LiveFrontier Applications (2023–2026)
LLM-Powered Work Tools
GitHub Copilot reaches 1M paid users, writing an estimated 46% of new code in supported files. Microsoft integrates GPT-4 into Office 365 as Copilot. ChatGPT Enterprise launches for regulated industries.
Multimodal & Agentic AI
GPT-4o, Gemini 1.5 Pro, and Claude 3 launch with native multimodal understanding. AI agents begin autonomously browsing the web, writing and executing code, completing multi-step tasks.
AI in Scientific Discovery
AlphaFold 3 extends protein prediction to DNA, RNA, and small molecules. AI-designed antibodies enter clinical trials. GNoME discovers 2.2M new stable crystal structures.
AI Reasoning & Autonomy
Reasoning models (OpenAI o3, Claude 3.7 Sonnet, Gemini 2.5 Pro) achieve near-expert performance on mathematical olympiads, competitive programming, and graduate-level science questions.
Industry Applications
AI, ML, and deep learning are transforming every major industry — not as future speculation, but in production systems operating today.
Healthcare
Diagnostic Imaging: CNNs detect diabetic retinopathy, lung cancer, and skin cancer at radiologist-level accuracy. Google’s LYNA identifies breast cancer metastases at 99% AUC.
Drug Discovery: Generative AI (RFdiffusion, AlphaFold 3) designs novel proteins and drug candidates, compressing timelines from decades to months.
Clinical NLP: LLMs extract structured data from notes, power virtual assistants, and draft documentation.
Personalised Medicine: ML predicts individual drug response and disease risk from polygenic scores.
Finance & Banking
Fraud Detection: Ensemble ML + DL scores every transaction in real time. JPMorgan’s CoiN handles in seconds what previously took 360,000 lawyer hours annually.
Algorithmic Trading: RL agents and time-series DL execute millions of trades/second.
Credit Scoring: Gradient boosting augments traditional scoring with behavioural and alternative data, expanding credit access.
Compliance: NLP monitors communications, flags suspicious activity, auto-generates reports.
Manufacturing
Predictive Maintenance: LSTM and temporal CNN on sensor data predict equipment failure hours to days in advance, reducing unplanned downtime by 20–50%.
Visual Quality Control: CNNs inspect products at superhuman speed and accuracy.
Supply Chain: ML forecasts demand, optimises inventory, reroutes logistics on disruptions.
Generative Design: AI explores millions of design variants meeting constraints, surfacing non-obvious optimal geometries.
Retail & E-Commerce
Recommendation Engines: Collaborative filtering + neural nets drive 35% of Amazon sales and 80% of Netflix views.
Dynamic Pricing: ML adjusts prices across millions of SKUs in real time.
Computer Vision Retail: Amazon Go uses vision + sensor fusion for checkout-free shopping.
Virtual Try-On: Diffusion models and GANs let customers visualise clothing, eyewear, and furniture before purchase.
Education
Adaptive Learning: ML personalises content sequencing to each learner’s knowledge state, adjusting difficulty in real time.
Intelligent Tutoring: LLMs provide Socratic dialogue, explain concepts, generate practice problems, give feedback on writing — 24/7 at zero marginal cost.
Early Intervention: Predictive models identify at-risk students from engagement patterns weeks before self-identification.
Language Learning: Speech recognition + NLP assess pronunciation and grammar with nuanced immediate feedback.
Climate & Energy
Grid Optimisation: DeepMind’s RL reduced Google data center cooling energy by 40%. ML forecasts wind/solar output to balance supply and demand.
Climate Modelling: ML accelerates climate simulations 1,000× vs traditional methods.
Wildfire & Flood Prediction: Satellite + CNN models detect early fire conditions and flood risk far better than rule-based systems.
Precision Agriculture: Vision + IoT optimise irrigation, detect crop disease early, target pesticide application.
Trends & The Road Ahead
The pace of progress in AI has defied even expert forecasts. Understanding the trajectories currently in motion is essential for anyone building, using, or governing AI systems.
Pre-training massive models on internet-scale data, then fine-tuning for specific tasks, is now the dominant paradigm. Compute-efficiency research (LoRA, QLoRA, quantisation) is making fine-tuning accessible to smaller organisations.
Trend 1The walls between text, image, audio, video, and code are dissolving. Frontier models natively process and generate across all modalities — GPT-4o, Gemini 1.5, Claude 3 signal the future.
Trend 2Reasoning models (o1, o3, Claude 3.7, Gemini 2.5 Pro) apply extended chain-of-thought before answering — dramatically improving performance on mathematics, coding, and scientific reasoning.
Trend 3AI moves from generating text to taking actions: browsing, writing and executing code, managing files, calling APIs. Agent frameworks (LangChain, AutoGen, Claude Computer Use) enable multi-step autonomous workflows.
Trend 4Distillation, INT4/INT8 quantisation, and hardware advances are bringing capable AI to smartphones, IoT, and embedded systems. Apple on-device ML, Qualcomm NPU models, Gemini Nano operate locally.
Trend 5The EU AI Act (2024), US Executive Orders, and voluntary safety commitments from major labs signal a new era. Explainability requirements, watermarking, and mandatory safety evaluations are becoming global baselines.
Trend 6Open Challenges
- Hallucination: LLMs still confidently generate plausible-sounding falsehoods. RAG and grounding help but don’t fully solve the problem.
- Alignment: Ensuring AI systems reliably do what humans intend — not just what they literally asked for — at scale and in novel situations.
- Interpretability: We cannot fully explain why large neural networks produce the outputs they do. Mechanistic interpretability is an active research frontier.
- Data & Compute Concentration: Training frontier models requires resources available only to a handful of organisations — raising questions about access and power.
- Energy Consumption: Training GPT-3 consumed ~1,287 MWh; inference at scale is rapidly becoming a major data-center power driver.
- Bias & Fairness: Models trained on historical data inherit and sometimes amplify societal biases. Evaluation and mitigation are necessary but not yet solved.
- Long-Context Reasoning: Context windows have expanded to millions of tokens, but models still struggle to reliably reason over very long documents.
“We are somewhere in the middle of the most important technology transition in human history. AI is not a product — it is a new way for intelligence to exist in the world. The practical question is not whether it will transform everything, but how fast, and who shapes the transformation.”
— Synthesised from AI research community, 2026AI is the destination. Machine Learning is the engine. Deep Learning is what made the engine powerful enough to matter at scale. Generative AI is the first mass-consumer application of that power. Each layer builds on the last — understanding the nesting hierarchy is the foundation for understanding every AI headline, product, and policy debate that will shape the next decade.
IBM’s authoritative reference comparing the four nested layers, with enterprise context.
Practical breakdown with comparison tables and code-oriented examples.
Engineering-focused comparison from Google Cloud’s discovery documentation.
Foundational definitions and the AI/ML relationship from Google’s learning hub.
Beginner-friendly walkthrough of AI, ML, and DL distinctions with learning paths.
Developer-oriented comparison covering generative AI and modern model architectures.
Academic perspective from IIT Kanpur covering all four layers in depth.
Tutorial-style reference with worked examples and visual hierarchy diagrams.
IT-services perspective on the four-layer hierarchy with deployment considerations.
Operations-focused comparison covering data volumes, infrastructure, and tooling.
2025 update from TDWI’s AI 101 series covering the latest reasoning models.
Data-quality perspective on how the four layers interact in production AI systems.